TL;DR: A side project I’m working on is a web interface for the photos collected by a smart scale. The scale and its attached camera is deployed in remote areas and as the fish are caught they are weighed on the scale and their picture is taken. There is a mobile app that coordinates all of that and when the user is back in an area with service / wifi, the photos are sent up to a bucket. The app that I’m working on allows scientists and other interested parties to review and analyze the batches of fish pulled from their fisheries / region. We’re using a combination of ML techniques and classical image processing to calculate fish lengths and species.
Background
This is not meant to be an ad for the product, though it’s pretty cool and automatically getting fish weight / length relationships per species is something that you’re into, get in touch with Todd at MER Consultants.
The sampling platform consists of a “sampler” - which is a package made up of a green board, scale, and a phone / camera. The idea is that as fish are pulled up, they’re slid onto the scale, it stabilizes, grabs a picture and records the weight and then they’re on to the next in only a few seconds. The hardware interface and software for that part of the system is an Android app in Kotlin that another dev is responsable for.

Once the pictures are offloaded to a bucket, typically after a big batch of sampling - that’s where the web app comes in. One of the web app’s background tasks indexes the bucket data into its database, and then kicks off background jobs to a region specific classifier for species detection, a pose estimation model to estimate specific points on the fish that scientists care about, and a classical detection algorithm to detect the edges of the green board / background that the fish is on.
Here’s what all those look like on an actual fish picture:
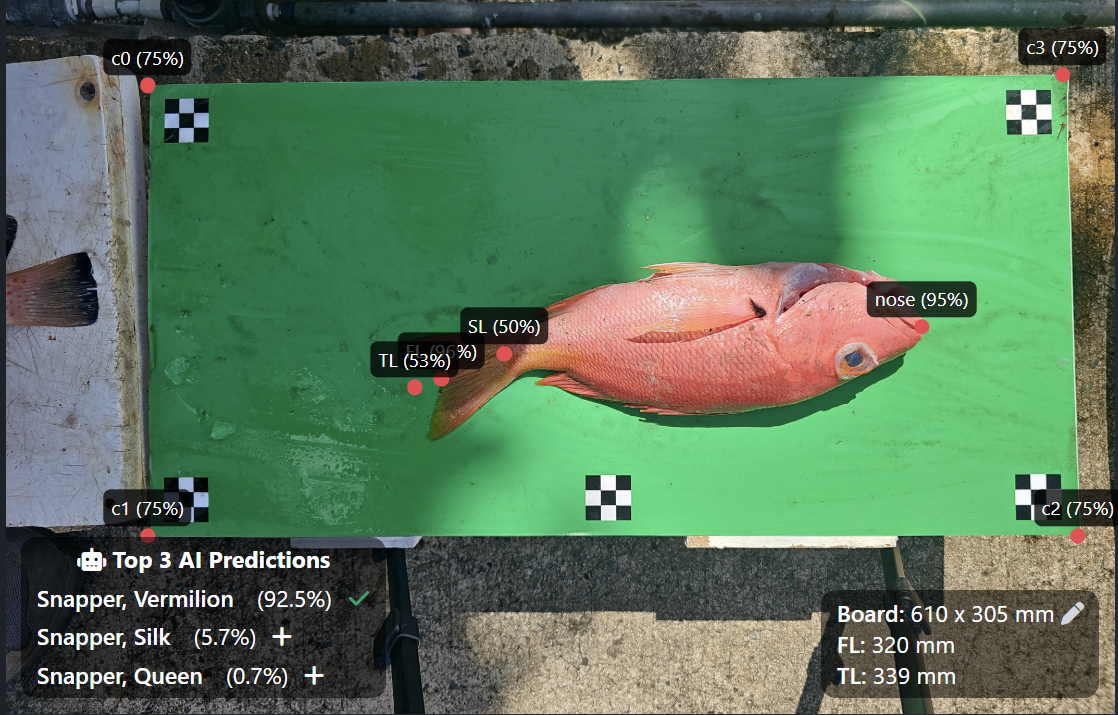
The idea is then that scientists, people managing the fisheries, etc, can then go into the app, see all the fish collected for their region, and generate reports with species counts, weights, lengths, etc - which is important to them to evaluate and model the health of the different species in their area. They can generate summary tables, export the data, and see length / weight relationships with the associated power law coefficients for the species, and spot outliers in the dataset - for example this for batch of a single species in a recent update:
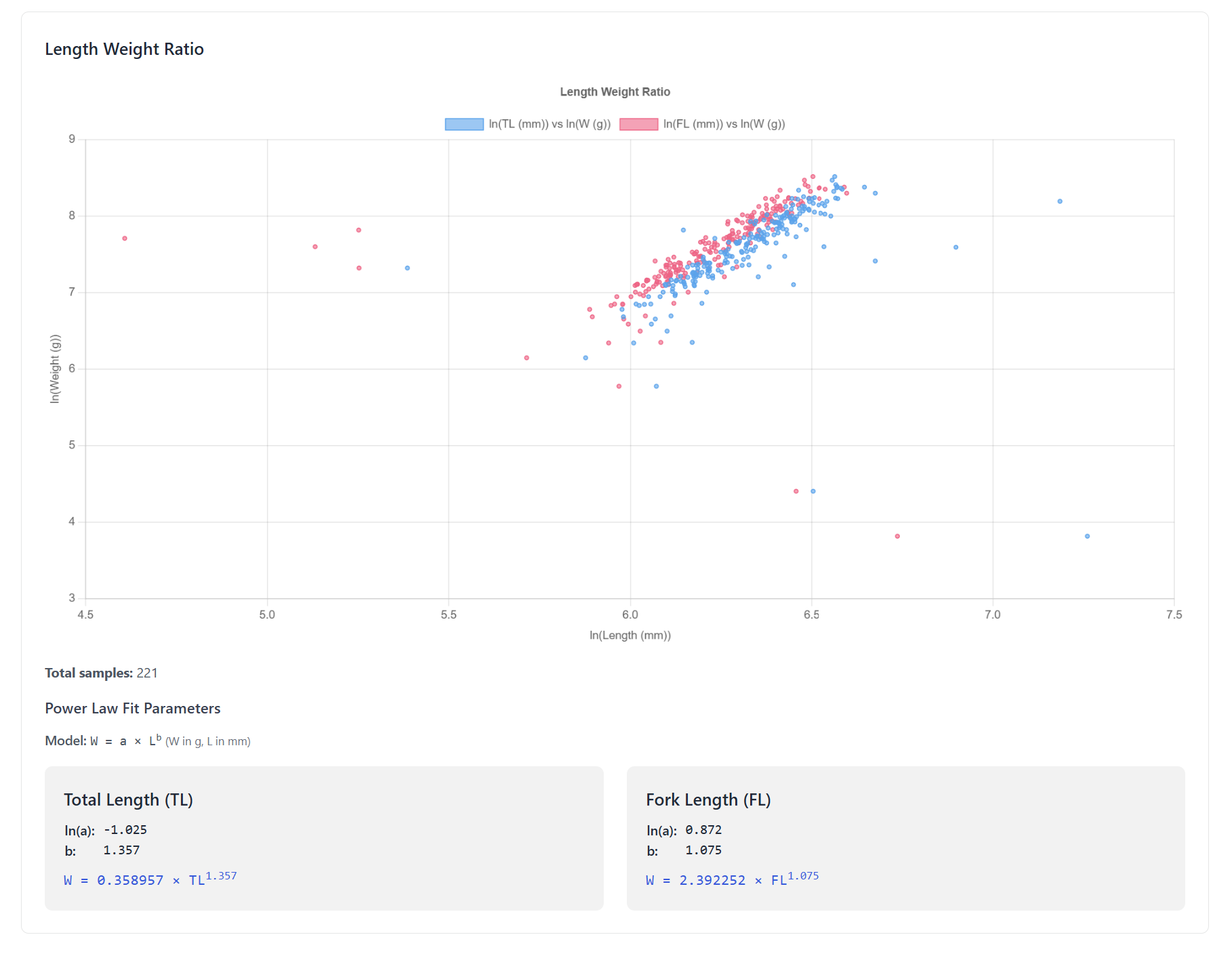
So that’s the idea, and it’s currently a work in progress - but we’ve got a lot done and I think it’s a really cool project.
Of course, I want to talk more about the tech stuff then the project in general, if fish talk is more what you’re looking for go elsewhere.
Structure
So we needed to get a web interface spun up quickly so that users could start see the pictures, annotate them, and see some preliminary reporting about the fish collected in their region. This doesn’t need to scale to a billion users, and the amount of client side user interaction needed for the app is minimal - for those reasons I went with Django and HTMX. . I know it’s not the most modern stack - but I’m super productive in it. It’s very batteries included, and when you don’t need a lot of client side interaction I think it’s the way to go. It let us spin everything up and start iterating very quickly.
Celery kicks off some async jobs that I don’t want to run in sync with requests - but most of the ML stuff runs totally separately on Google Cloud Platform. The main reason being that dependencies and resources needed for each of the ML steps are way different - it was easier to set them up to run as their own services with their own sandboxed dependencies. The jobs are triggered async from the Django app via pub/sub, the service runs the ML job on the photo and then sends the results back to the Django app view a webhook. They can all independently spin up a few more instances when big batches come in because processing the images is kind of slow. It was a good tradeoff to me to keep services totally self contained - not interacting with the actual database, etc. There are nice clean lines there and they all do one specific job (process this photo and dump out the results).
Some of the simple interactions use HTMX - for each sample, you can apply a species. There’s a filter dropdown on each one and the search uses HTMX to narrow down the available species as you type. Saving the species to the sample also uses HTMX - it posts the selection and returns the select input component back with an error or success message to be swapped in. The same approach works great for other labels too, text fields, generic option fields, etc. I also used it in some of the modals - so when the modal is triggered to open the content is requested and swapped in. I also used it in a two stage modal - it works something like: here’s a modal with a list of the species that the user wants to add, if you click edit, the modal swaps in a form with the species fields to be corrected and then saved, and then the list or a “you’re all done” state swaps in.
Some elements sync using events to avoid needing to do an out of band swap or something else - for example, the length of the fish is calculated using the known size of the board in the background. If the board size is changed, it fires off an event that will trigger the element that displays length to request itself again.
There’s one aspect of the app where I feel I should have used React though, or any other popular frontend framework. As things have progressed, the scope of functionality needed in the “detail view” for an image has expanded a lot. It’s becoming more and more like an image annotator than a simple “review and apply some tags” kind of deal. I wrote the first pass in just raw vanilla JS (and a bit of typescript fwiw) in all the places where HTMX didn’t make sense - but it’s overly complex (yes my fault). A lot of manual DOM manipulation to be able to draw annotations of different kinds on the images, delete them, pan, zoom, etc, all client side before sending back to the server. I already have a build system set up for my front end files, so when I have a bit of refactor time I’m going to rewrite this component using Alpine or maybe React and have it talk to the server via JSON like the kids these days want me to. I think that will make managing the state and all the interactions / updates in this component way cleaner and easier to maintain, especially if some more devs get brought on to help out.
The sync part of the image annotation component was also a little tricky, and at least with the way I think about things a bit trickier managing it all without something like React. If editing the same photo in two tabs, or if two people were working on the same photo separately, work could be overwritten / lost. Of course, the edits could be merged using operational transformation or some other robust approach. The simpler approach I went with for now was to add a version to the annotations - increment it each update, and let the app poll for the annotations periodically. If it polls and gets a new version, it displays it right away and the user will see the new changes. If the current user is editing and it receives a new version, it will not allow the update and they will see an error letting them know they don’t have the latest version - if it tries to save a users updates but there’s already been a new version, same thing it will return an error.
Detection Models
I can’t give a too many of the details here but we’re also working with another eng (ML guy) who’s been responsible for developing, training and fine-tuning the models. They get passed of to me for deployment. The classifiers are fine-tuned on the specific species each region so that they perform much better then the generalized models. Some of those are publicly available and very cool - but fine-tuning on 20 - 30 species is always better than a generalized model trying to get many 100’s correct, at least as far as I’ve seen.
The “keypoint” detection is a pose estimation model trained on a bunch of annotations by researchers. Basically they label the start of the fish, then there are different ways to record its length, so all those points are generated by the model.
The final part is finding the corners of the background board - with the corners of the board marked in the image and the known board size we can calculate the lengths to all of the relevant points on the fish. This is actually pretty cool - as the board can be rotated and tilted slightly out of plan - we used transformation to flatten it back out, like your phone might do in detecting a document. Once that translation is known, we apply it to annotations to get them all un-warped too, and it gives a much more accurate value.
Here’s a visual example of some of the steps in the processing starting with a normal RGB image and doing different masking, filtering, and thresholding before detecting the edges, lines, corners, and finally, the four point transform to flatten it out / rotate it. All of this brought to you by OpenCV…
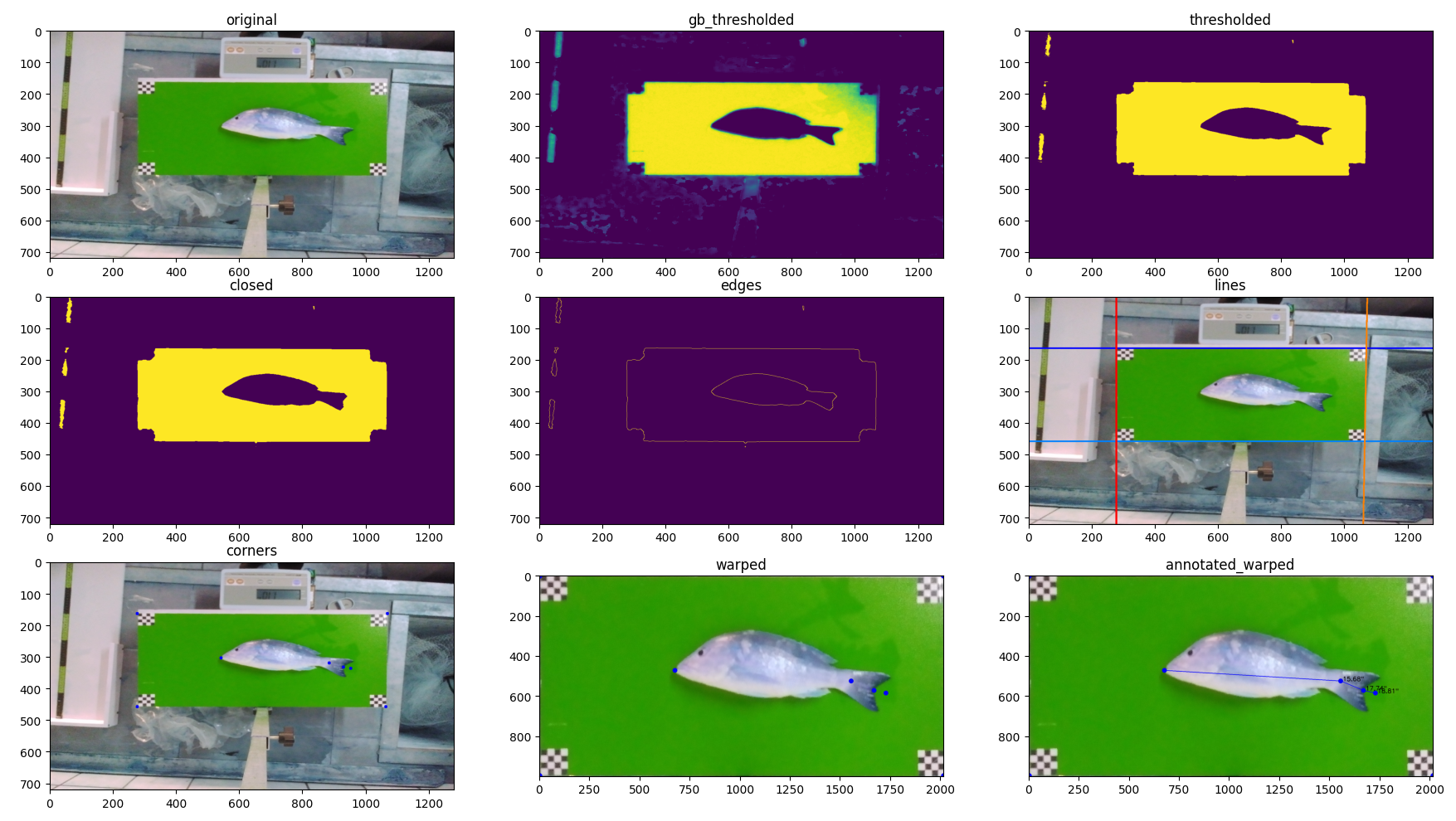
Of course an ML based approach might be able to generalize better and handle worse lighting conditions, etc, but they’re also more expensive to train and run, so it’s a tradeoff again and this has been working great for now.
I did see the recent release of SAM3 and seems like we might be able to use that model to find the board at least. Lot’s more to test out, and we’re building out more and futures as more regions come online and have slightly different needs… but that’s the update!
That’s all I got
Still on going - so hopefully I’ll have more to add as time goes on.
I guess I learned so far I learned:
- I really like the combo of Django and HTMX for a lot of things, don’t really care if it’s regarded as outdated - “what is dead may never die” lol
- I’m happy to use React when needed - kicking myself for not switching that annotator component to React sooner
- Prefetch! Profile of course but if you have tags, labels, etc, all “properly” normalized in your database and they’re connected to the main table via associative or “joining” tables - things start to get really slow if you’re not prefetching related stuff when you need to. Using prefetching with annotations to sort of cache some lookups (top three species by a given model for a picture for example) was a big help vs not doing using it. Easy to accidently end up with “N+1 queries” hidden by the ORM. I’m also going to start caching a bunch of these labels in the actual photo table - de-normalizing I know - but we had a couple big data dumps come in and I learned where the performance issues were really quickly :)
- If you use Pub/Sub messages to trigger services - better make sure that ack deadline isn’t shorter than the duration of time that service usually needs to process the request - 🤦♂️ - managed to basically ddos my own service and couldn’t figure out why for a bit…